Used Flag
This is the detailed story of my Tweet about the used flag.
Database Reduction
Some background first. CDCL solvers learns clauses. Actually they generate way too many clauses to keep all of them. So you have to remove them. Actually many of them. This happens during so-called reductions.
This comes from the theory of CDCL. There are two way to keep completeness: either delay restarts more-and-more or keep more-and-more clauses. But this does not tell you which clauses you have to keep during reductions.
The very first question is which clauses do we actually have to keep? So actually you have to:
- keep the initial clauses (or the strengthened initial clauses), called the irredundant clauses
- keep the clauses that are used in the trail (because well, they are currently used)
- the binary clauses for technical reasons (to avoid cleaning the watch lists after each reduction)
The Isabelle code looks like:
OBTAIN can_del WHERE can_del --> not used in trail \<and>
status = LEARNED \<and>
length \<noteq> 2;
if can_del
then (*delete it*)
else (*keep it*)
The Actual Heuristic
The flag can_del indicates that we are allow to delete the code, but
do not have to it.
The critical question is: which ones do you keep in a practical solver? On the one side, we know that 80\% of the unit propagation are useless, so there is a high likelyhood that a clause is used only once or twice. On the other side, in practice, we know that learning is very important.
How does the code look like? Well the more concrete version says that:
let can_del = not used in trail \<and>
lbd > MINIMUM_DELETION_LBD \<and>
status = LEARNED \<and>
length \<noteq> 2 \<and>
used > 0;
if can_del
then (*delete it*)
else (*keep it*)
This tells us that we fullfill the theoretical conditions but also:
- keep clauses of small LBD. This idea was pioneered by Glucose.
- keep used clauses. This is newer heuristic. It was in particular the intuition of Armin Biere and one of the contribution of Mate Soos et other in CrystalBall (Mate Soos has a much better blog that I do!).
Actually, I use a 2-tier version that is also in Kissat. The used flag takes 3 values: ‘unused’ (value 0), ‘used one’ (value 1, tier 1), and ‘used twice’ (value 2, tier 2). Only small clauses can enter tier 2.
Anyway, any clause that was used survives the next reduction phase
independantly of its score. Tier 2 clauses actually survive two
reductions phases before being considered for deletion. Do you see the
bug now in the code above? Indeed, used>0 is obviously not the
intended heuristic.
Here is a CDF (keep the solver that finished last during the SAT Competition 2021, on those benchmarks):
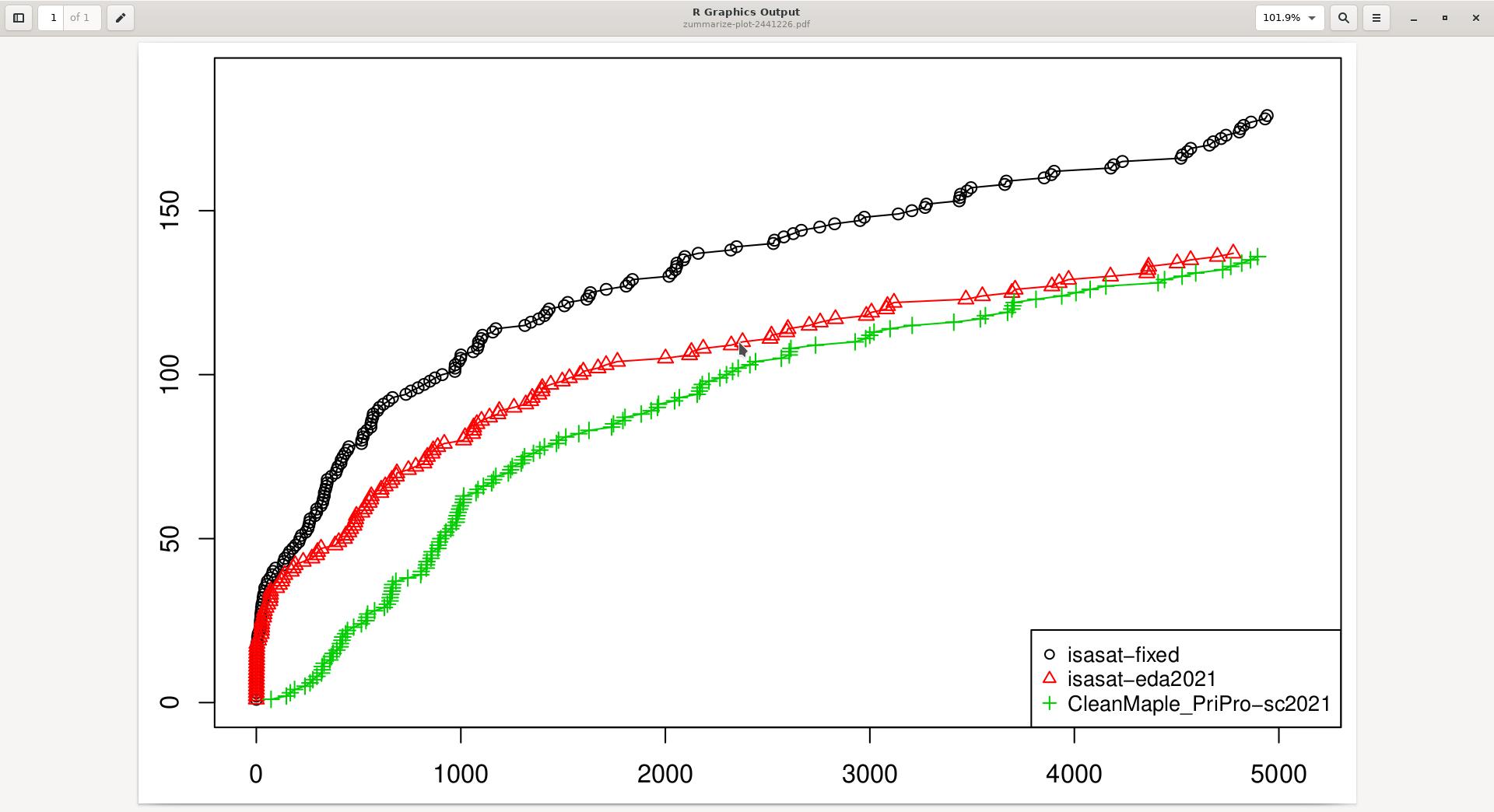
So, fixing the heuristic clearly improved performance.
What was I actually trying to do?
I was working with a different goal actually, but a performance improvement is obviously nice.
The old code looked like:
sort the indices of all learned clauses
j <- number of clauses to keep
for i = j to end do
if can_del
then remove clause at i
else keep clause at i
The new version now is:
candidate_clauses <- []
for i = 0 to end do
if can_del
then push the clauses to st
else keep it
sort the indices of candidate_clauses
for i = j to end do
remove clause at i
This should reduce the number of clauses to sort, which is important time factor. Actually very early I had a list of all clauses (learned + irredundant) and was sorting that one – because it was easier to prove–, but the generated code was way too slow to be useful.
Conclusion
I don’t think there is anything to learn to about the mistake, except that reviewing your own code every once in a while is useful. Isabelle cannot help us here, because I do not know to write a specification for such heuristics.